![]()
1.Introdução
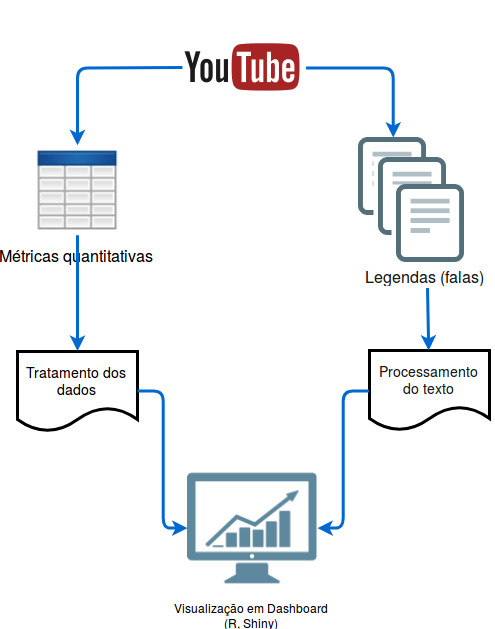
Abordarei neste tópico uma forma de explorar informações contidas em um determinado canal do Youtube. Como exemplo, estarei demonstrando a obtenção e análise dos dados proveniente do canal “Nerdologia”, dos autores Atila Iamarino e Filipe Figueiredo. Os dados manipulados servem como base para a apresentação gráfica em um dashboard dinâmico, desenvolvido em Shiny (linguagem R). Por hora, proponho a análise quantitativa de métricas como visualizações, likes, dislikes e comentários. Bem como a análise textual das legendas geradas automaticamente pelo sistema do Youtube (quando habilitado pelo(s) autor(es) do canal).
Infelizmente o acesso ao texto completo dos comentários é limitado pela API do Youtube, portanto eles não foram analisados (motivos financeiros). A motivação para este estudo é meramente e unicamente por uma questão de curiosidade e pelo exercício da criatividade. Bem como uma forma divertida de se aperfeiçoar cada vez mais nas ferramentas da linguagem R (programação, métodos de exploração de dados, desenvolvimento de dashboards, etc.).2.Metodologia
Primeiramente foi realizada a extração dos dados brutos. Para as métricas quantitativas, utilizei a API do Youtube (necessita de cadastro prévio) via pacote tuber do R. As legendas automáticas foram baixadas usando o pacote RCurl juntamente com a ferramenta online diycaptions ( http://diycaptions.com).
Os dados textuais foram processados pelas funções do pacote tm e visualizados usando a ferramenta wordcloud. No caso das métricas quantitativas do canal, os dados foram visualizados pela ferramenta plotly. A visualização foi realizada dentro de um dashboard desenvolvido em shiny.
Carregando as bibliotecas
library(rvest)
library(ggplot2)
library(dplyr)
library(tidyr)
library(lubridate)
library(plotly)
library(tuber)
library(stringr)
library(tm)
library(wordcloud)
library(RCurl)
library(VennDiagram)
library(kableExtra)2.1.Extraindo métricas do canal
Primeiramente precisamos fazer a autenticação da nossa conta para poder acessar os dados do Youtube. É preciso realizar um cadastro prévio no site e fazer a requisição de chave de acesso (https://developers.google.com/youtube/v3/).
client_id <- 'xxxxxxxx'
key <- 'xxxxxxxx'
yt_oauth(client_id, key)
all_vid_nerdologia <- get_all_channel_video_stats(channel_id= 'UClu474HMt895mVxZdlIHXEA', mine= FALSE)Precisamos formatar ele adequadamente, formatando os tipos de variáveis bem como fazendo uma limpeza na variável dos títulos.
# Dates
date_split_list <- strsplit(x= as.character(all_vid_nerdologia$publication_date), split= 'T')
date_split_list <- lapply(date_split_list, function(x){x[1]}) %>% unlist()
all_vid_nerdologia['publication_date'] <- date_split_list
all_vid_nerdologia$publication_date <- as.Date(all_vid_nerdologia$publication_date)
# Variable class
all_vid_nerdologia$viewCount <- as.numeric(all_vid_nerdologia$viewCount)
all_vid_nerdologia$likeCount <- as.numeric(all_vid_nerdologia$likeCount)
all_vid_nerdologia$dislikeCount <- as.numeric(all_vid_nerdologia$dislikeCount)
all_vid_nerdologia$favoriteCount <- as.numeric(all_vid_nerdologia$favoriteCount)
all_vid_nerdologia$commentCount <- as.numeric(all_vid_nerdologia$commentCount)
# Cleanning data title
all_vid_nerdologia$title <- gsub('\\s\\|\\s.*$', '', all_vid_nerdologia$title)Top 10 vídeos com mais Likes
all_vid_nerdologia %>%
arrange(desc(likeCount)) %>%
head(10) %>%
select(title, likeCount, dislikeCount, commentCount) %>%
kable("html") %>%
kable_styling("striped", full_width= F) %>%
column_spec(1:4, bold= T) %>%
row_spec(1:10, bold= T, color= "white", background= "#3399ff")| title | likeCount | dislikeCount | commentCount |
|---|---|---|---|
| Suicídio | 114725 | 695 | 5853 |
| Buraco Negro | 113815 | 422 | 4076 |
| Tempo | 104740 | 303 | 3456 |
| CAOS E EFEITO BORBOLETA | 101124 | 423 | 2719 |
| AS MARCAS TE MANIPULAM | 101039 | 305 | 2441 |
| QUAL O SOCO MAIS FORTE? | 101037 | 595 | 6967 |
| SER INVISÍVEL É POSSÍVEL? | 100276 | 221 | 2531 |
| LEVANTE ZUMBI | 99738 | 294 | 3454 |
| O que somos nós? | 98443 | 308 | 4006 |
| Mistérios do Fundo do Mar | 97193 | 577 | 2506 |
Top 10 vídeos com mais Dislikes
all_vid_nerdologia %>%
arrange(desc(dislikeCount)) %>%
head(10) %>%
select(title, dislikeCount, likeCount, commentCount) %>%
kable("html") %>%
kable_styling("striped", full_width= F) %>%
column_spec(1:4, bold= T) %>%
row_spec(1:10, bold= T, color= "white", background= "#ff3333")| title | dislikeCount | likeCount | commentCount |
|---|---|---|---|
| Sexismo | 13984 | 93561 | 15642 |
| Quem tem mais poder? | 4093 | 91474 | 14424 |
| Existe cura gay? | 2787 | 83583 | 6110 |
| Aquecimento Global | 1854 | 49424 | 3921 |
| Como funciona a Astrologia | 1793 | 74924 | 5447 |
| Maioridade Penal | 1721 | 68294 | 3179 |
| Por que o Merthiolate não arde mais? | 1657 | 59323 | 2362 |
| Motor perpétuo? Carro a água? | 1629 | 52140 | 3355 |
| Coxinhas vs. Petralhas | 1312 | 59094 | 3632 |
| Batman vs Superman | 1175 | 66649 | 2337 |
Top 10 vídeos com mais comentários
all_vid_nerdologia %>%
arrange(desc(commentCount)) %>%
head(10) %>%
select(title, commentCount, dislikeCount, likeCount) %>%
kable("html") %>%
kable_styling("striped", full_width= F) %>%
column_spec(1:4, bold= T) %>%
row_spec(1:10, bold= T, color= "white", background= "#4d9900")| title | commentCount | dislikeCount | likeCount |
|---|---|---|---|
| Sexismo | 15642 | 13984 | 93561 |
| Quem tem mais poder? | 14424 | 4093 | 91474 |
| QUAL O SOCO MAIS FORTE? | 6967 | 595 | 101037 |
| É só uma teoria | 6120 | 690 | 92609 |
| Existe cura gay? | 6110 | 2787 | 83583 |
| Suicídio | 5853 | 695 | 114725 |
| Como funciona a Astrologia | 5447 | 1793 | 74924 |
| Fomos à Lua? | 5132 | 1120 | 64036 |
| COMO MATAR O WOLVERINE | 4979 | 488 | 89501 |
| POSSESSÃO, ABDUÇÃO OU PARALISIA DO SONO? | 4901 | 355 | 90767 |
Agora, deixarei salvo o objeto da tabela processada, para carregar dentro do meu dashboard.
save(file= 'all_vid_nerdologia.RData', all_vid_nerdologia)2.1.Extraindo dados textuais das legendas e formatando
A função do pacote tuber que realiza a extração das legendas não está funcionando mais, por isso eu optei por um modo semi-rudimentar para fazer isso (porque demora um pouco :/). Tive que colocar um delay de 30 segundos em cada requisição pois se formos muito rápido acabamos tendo a conexão interrompinda.
url_request <- paste0('http://diycaptions.com/php/get-automatic-captions-as-txt.php?id=', all_vid_nerdologia$id, '&language=asr')
html_page <- list()
for(i in 1:length(url_request) ){
html_page[i] <- getURL(url_request[i])
Sys.sleep(30)
}
save(file= 'html_page.RObj', html_page)Precisarei da minha lista de texto ordenado pela data quanto for retornar um index do plot
all_vid_nerdologia['index'] <- 1:nrow(all_vid_nerdologia)
all_vid_nerdologia <- all_vid_nerdologia %>% arrange(publication_date)
html_page_text_sorted <- html_page_text[all_vid_nerdologia$index]
save(file='html_page_text_sorted.RData', html_page_text_sorted)Agora farei o pré-tratamento dos dados textuais e a limpeza propriamente dita
# Removing tags blocks
html_page_text <- lapply(html_page, function(x){
split_1 <- strsplit(x[[1]], '<br><br>')[[1]][2]
strsplit(split_1[[1]], '\t\t</div>')[[1]][1]
})
# Saving object for individual process
# save(file = 'html_page_text.RData', html_page_text)
# Generating corpus text for all avaiable data
text_df_total <- data.frame(doc_id= all_vid_nerdologia$id, text= unlist(html_page_text), stringsAsFactors= FALSE , drop=FALSE)
text_corpus_df <- Corpus(DataframeSource(text_df_total))
text_corpus_df_filtered <- text_corpus_df %>%
tm_map(stripWhitespace) %>%
tm_map(removePunctuation) %>%
tm_map(removeNumbers) %>%
tm_map(removeWords, c(stopwords("portuguese"))) %>%
tm_map(removeNumbers) %>%
tm_map(stripWhitespace) %>%
tm_map(content_transformer(tolower))
# Creanting a term matrix
corpus_tf <- TermDocumentMatrix(text_corpus_df_filtered)
corpus_m <- as.matrix(corpus_tf)
corpus_m_sorted <- sort(rowSums(as.matrix(corpus_m)), decreasing= TRUE)
df_total <- data.frame(word= names(corpus_m_sorted), freq= as.numeric(corpus_m_sorted))
df_total$word <- as.character(df_total$word)
df_total <- df_total[which(nchar(df_total$word) > 4), ]O gráfico de frequência total das palavras também deverá aparecer. Porém, lá na ferramenta irei adicionar mecanismos de controle de filtro.
wordcloud(df_total$word, df_total$freq, min.freq= 10, max.words= 150, random.order= FALSE, rot.per= 0.35, colors=brewer.pal(8, "Dark2"))

Farei também uma word cloud para os títulos dos vídeos postados
text_df_total <- data.frame(doc_id= all_vid_nerdologia$title, text= all_vid_nerdologia$title, stringsAsFactors= FALSE , drop=FALSE)
text_corpus_df <- Corpus(DataframeSource(text_df_total))
text_corpus_df_filtered <- text_corpus_df %>%
tm_map(stripWhitespace) %>%
tm_map(removePunctuation) %>%
tm_map(removeNumbers) %>%
tm_map(removeWords, c(stopwords("portuguese"))) %>%
tm_map(removeNumbers) %>%
tm_map(stripWhitespace) %>%
tm_map(content_transformer(tolower))
# Creanting a term matrix
corpus_tf <- TermDocumentMatrix(text_corpus_df_filtered)
corpus_m <- as.matrix(corpus_tf)
corpus_m_sorted <- sort(rowSums(as.matrix(corpus_m)), decreasing= TRUE)
df_total <- data.frame(word= names(corpus_m_sorted), freq= as.numeric(corpus_m_sorted))
df_total$word <- as.character(df_total$word)
df_total_titulo <- df_total[which(nchar(df_total$word) > 2), ]
wordcloud(df_total_titulo$word, df_total_titulo$freq, min.freq= 2, max.words= 100, random.order= FALSE, rot.per= 0.35, colors=brewer.pal(8, "Dark2"))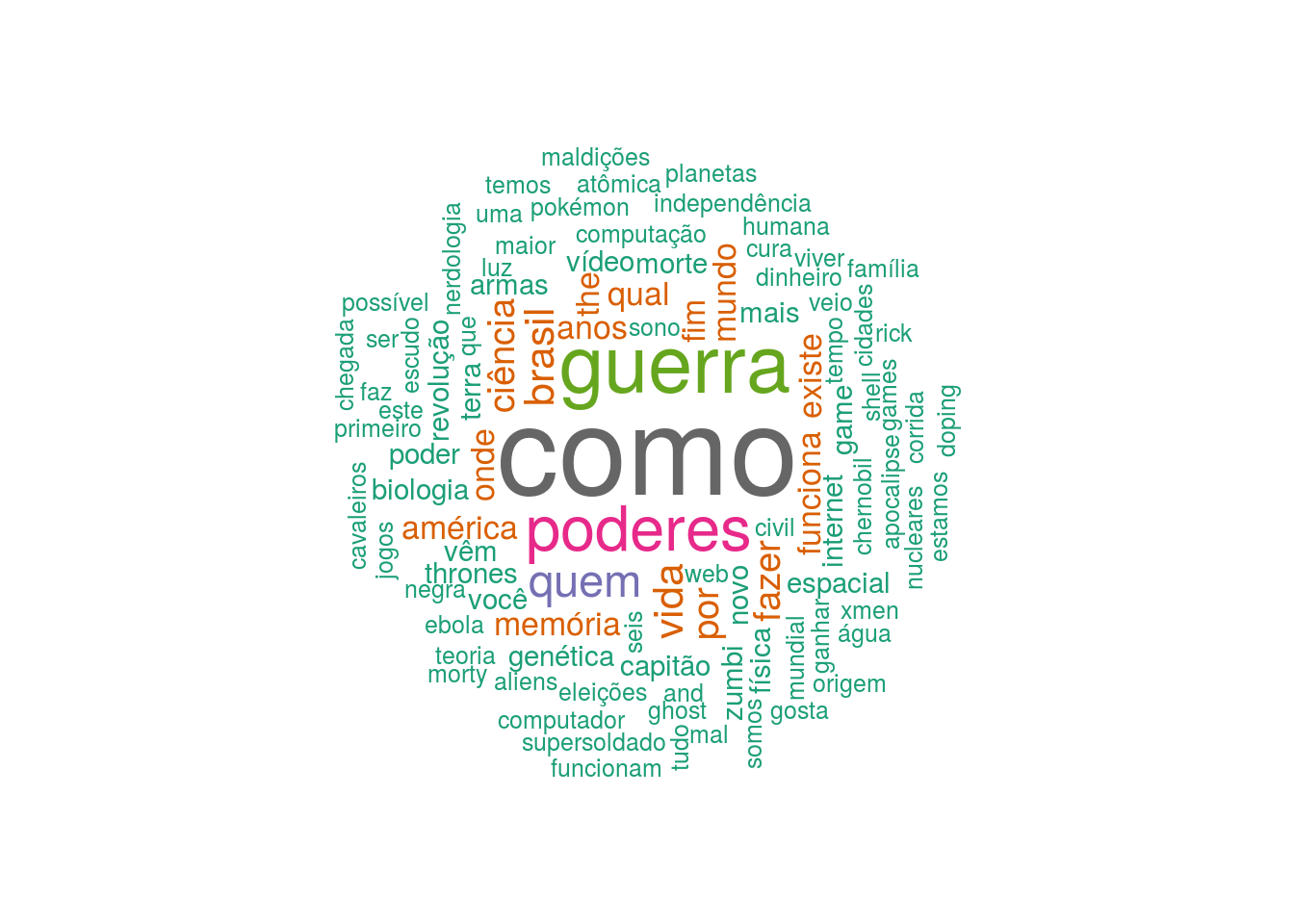
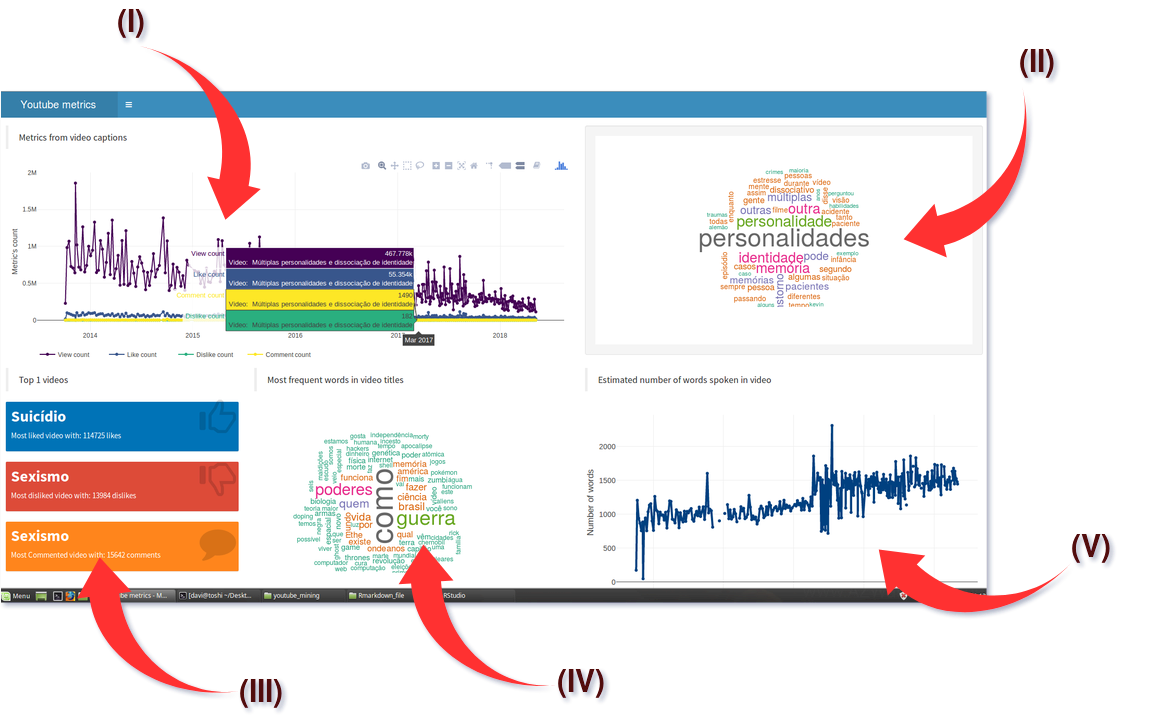
O gráfico do dashboard deve ser similar a este, porém, responsivo com mais informações e opções de filtro.
all_vid_nerdologia %>%
gather(key= type_counts, value= counts,
c(likeCount, dislikeCount, commentCount, viewCount)) %>%
filter(str_detect('likeCount|dislikeCount|commentCount', type_counts)) %>%
ggplot(aes(x= publication_date, y= as.numeric(counts), col= type_counts)) +
geom_line(size=1, alpha=0.7) +
geom_point(size=1) +
scale_x_date() +
theme_bw() +
scale_color_manual(values = c('#440154FF', '#39568CFF', '#29AF7FFF'))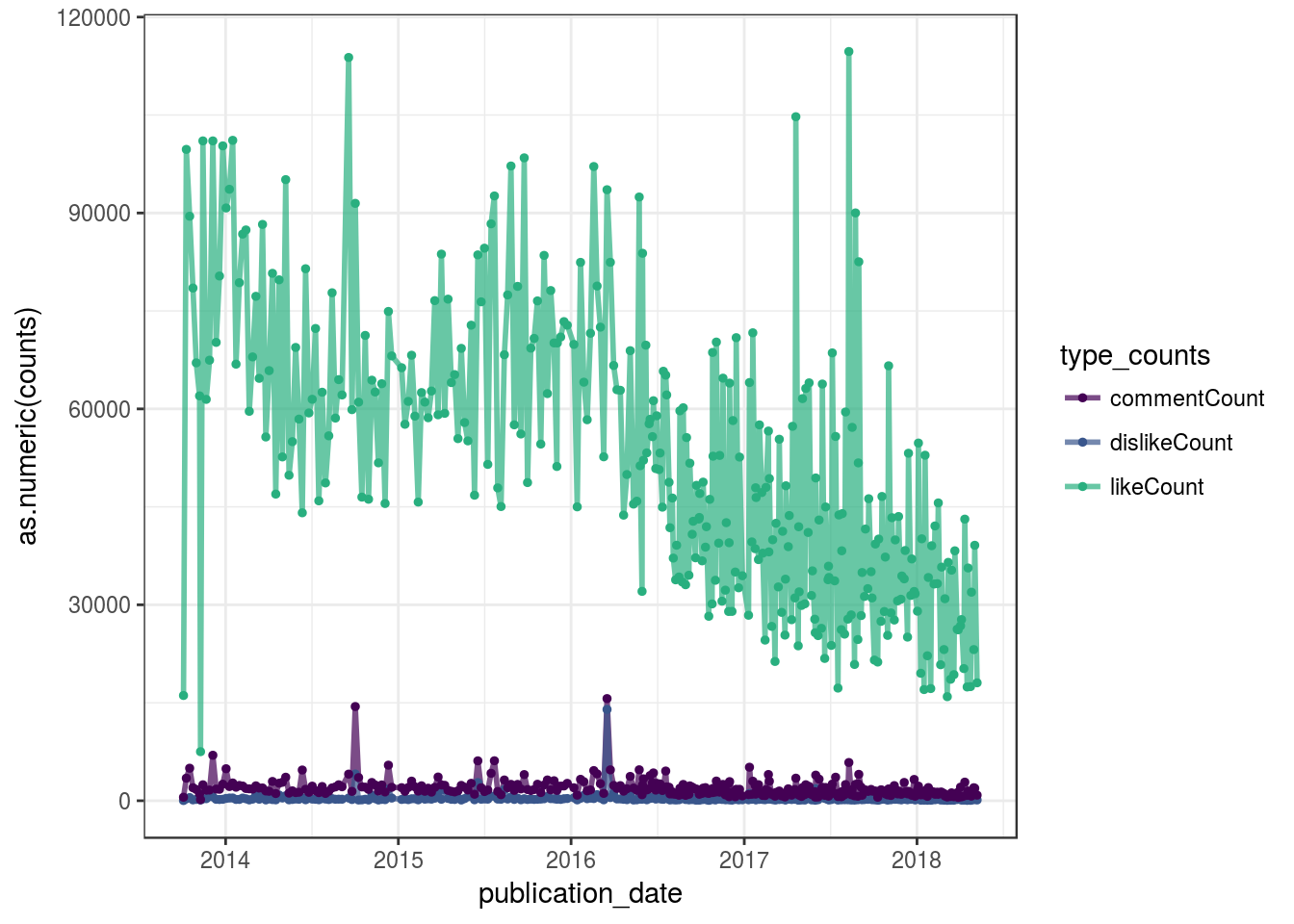
Criando um dashboard dinâmico
Para prover uma visualização diferenciada dos dados, optei por criar um dashboard dinâmico, reativo ao cursor do mouse e que também aceita diferentes parâmetros para gerar os resultados. Assim, podemos abranger um pouco mais do nosso aprendizado. :D
No dashboard, os dados da métrica e os dados textuais são carregados pré-processados. No caso, ele irá apenas realizar a apresentação dinâmica dos resultados.
Este é o código, também disponível no github (por favor, não fiquei com raiva pela desorganização).
library(shinydashboard)
library(highcharter)
library(ggplot2)
library(dplyr)
library(plotly)
library(tm)
library(wordcloud)
library(VennDiagram)
library(kableExtra)
load('all_vid_nerdologia.RData')
load('html_page_text.RData')
load('html_page_text_sorted.RData')
ui <- dashboardPage(
# Header ----
dashboardHeader(title = "Youtube metrics"),
# Sidebar content ----
dashboardSidebar(collapsed = TRUE,
sidebarMenu(
menuItem("Dashboard", tabName = "dashboard", icon = icon("dashboard"))
)
),
# Body content ----
dashboardBody(
includeCSS("www/custom.css"),
tabItems(
# First tab content
tabItem(tabName= "dashboard",
fluidRow(
column(width= 7,
tags$blockquote(("Metrics from video captions")),
plotlyOutput(outputId = 'metrics_total_plot', height= '400px')
),
column(width= 5,
wellPanel(
plotOutput(outputId= 'cursor_wc_plot', height= '400px')
)
)
),
fluidRow(
column(3,
tags$blockquote(("Top 1 videos")),
valueBoxOutput("likebox", width = 15),
valueBoxOutput("dislikebox", width = 15),
valueBoxOutput("commentbox", width = 15)
),
column(4,
tags$blockquote("Most frequent words in video titles", align="left"),
plotOutput(outputId= 'title_wc_plot', width=500, height=400)
),
column(5,
tags$blockquote("Estimated number of words spoken in video", align="left"),
plotlyOutput(outputId = 'numb_spoken_words', height= '400px')
)
)
)
)
)
)
server <- function(input, output){
# Plot wordcloud total ----
output$metrics_total_plot <- renderPlotly({
all_vid_nerdologia %>%
arrange(publication_date) %>%
plot_ly(source = "source") %>%
add_trace(x = ~publication_date, y = ~viewCount,
name = 'View count', type = 'scatter',
mode ="markers+lines", text = ~paste('Video: ', title),
line = list(color = '#440154FF ', width = 2)) %>%
add_trace(x = ~publication_date, y = ~likeCount,
name = 'Like count', type = 'scatter',
mode ="markers+lines", text = ~paste('Video: ', title),
line = list(color = '#39568CFF', width = 2)) %>%
add_trace(x = ~publication_date, y = ~dislikeCount,
name = 'Dislike count', type = 'scatter',
mode = "markers+lines", text = ~paste('Video: ', title),
line = list(color = '#29AF7FFF', width = 2)) %>%
add_trace(x = ~publication_date, y = ~commentCount,
name = 'Comment count', type = 'scatter',
mode = "markers+lines", text = ~paste('Video: ', title),
line = list(color = '#FDE725FF', width = 2)) %>%
layout(xaxis = list(title = ""),
yaxis = list (title = "Metric's count"),
font = list(size = 12),
hovermode = 'compare',
legend = list(orientation = 'h'))
})
# Plot over cursor selected word cloud ----
output$cursor_wc_plot <- renderPlot({
eventdata <- event_data("plotly_hover", source = "source")
validate(need(!is.null(eventdata), "Pass the mouse over the point :)"))
cursor_id <- as.numeric(eventdata$pointNumber)[1] + 1
all_vid_nerdologia <- all_vid_nerdologia %>%
arrange(publication_date)
text_df_cursor <- data.frame(doc_id= all_vid_nerdologia$id[ cursor_id ],
text= unlist(html_page_text_sorted[ cursor_id ]),
stringsAsFactors= FALSE , drop=FALSE)
cursor_corpus_df <- Corpus(DataframeSource(text_df_cursor))
cursor_corpus_df_filtered <- cursor_corpus_df %>%
tm_map(stripWhitespace) %>%
tm_map(removePunctuation) %>%
tm_map(removeNumbers) %>%
tm_map(removeWords, c(stopwords("portuguese"))) %>%
tm_map(removeNumbers) %>%
tm_map(stripWhitespace) %>%
tm_map(content_transformer(tolower))
# Creanting a term matrix
corpus_tf <- TermDocumentMatrix(cursor_corpus_df_filtered)
cursor_corpus_m <- as.matrix(corpus_tf)
cursor_corpus_m_sorted <- sort(rowSums(as.matrix(cursor_corpus_m)), decreasing= TRUE)
df_cursor_final <- data.frame(word= names(cursor_corpus_m_sorted), freq= as.numeric(cursor_corpus_m_sorted))
df_cursor_final$word <- as.character(df_cursor_final$word)
df_cursor_final <- df_cursor_final[which(nchar(df_cursor_final$word) > 3), ]
wordcloud(df_cursor_final$word, df_cursor_final$freq, min.freq = 2, max.words= 50,
random.order= FALSE, colors=brewer.pal(8, "Dark2"), scale=c(4, 0.5))
})
# Metrics top videos box ----
# Like box
output$likebox <- renderValueBox({
toplike <- all_vid_nerdologia %>%
arrange(desc(likeCount)) %>%
head(10)
valueBox(value = tags$p(toplike$title[1], style = "font-size: 80%;"),
subtitle = paste0("Most liked video with: ", toplike$likeCount[1], " likes"),
icon = icon("thumbs-up", lib = "glyphicon"),
color = "blue"
)
})
# Dislike box
output$dislikebox <- renderValueBox({
topdislike <- all_vid_nerdologia %>%
arrange(desc(dislikeCount)) %>%
head(10)
valueBox(value = tags$p(topdislike$title[1], style = "font-size: 80%;"),
subtitle = paste0("Most disliked video with: ", topdislike$dislikeCount[1], " dislikes"),
icon = icon("thumbs-down", lib = "glyphicon"),
color = "red"
)
})
# Comments box
output$commentbox <- renderValueBox({
topcomment <- all_vid_nerdologia %>%
arrange(desc(commentCount)) %>%
head(10)
valueBox(value = tags$p(topcomment$title[1], style = "font-size: 80%;"),
subtitle = paste0("Most Commented video with: ", topcomment$commentCount[1], " comments"),
icon = icon("comment", lib = "font-awesome"),
color = "orange"
)
})
# Word cloud topic's titles plot ----
output$title_wc_plot <- renderPlot({
title_df <- data.frame(doc_id= all_vid_nerdologia$title, text= all_vid_nerdologia$title, stringsAsFactors= FALSE , drop=FALSE)
title_corpus <- Corpus(DataframeSource(title_df))
title_corpus_filtered <- title_corpus %>%
tm_map(stripWhitespace) %>%
tm_map(removePunctuation) %>%
tm_map(removeNumbers) %>%
tm_map(removeWords, c(stopwords("portuguese"))) %>%
tm_map(removeNumbers) %>%
tm_map(stripWhitespace) %>%
tm_map(content_transformer(tolower))
# Creanting a term matrix
corpus_tf <- TermDocumentMatrix(title_corpus_filtered)
corpus_m <- as.matrix(corpus_tf)
corpus_m_sorted <- sort(rowSums(as.matrix(corpus_m)), decreasing= TRUE)
df_total <- data.frame(word= names(corpus_m_sorted), freq= as.numeric(corpus_m_sorted))
df_total$word <- as.character(df_total$word)
df_total_titulo <- df_total[which(nchar(df_total$word) > 2), ]
wordcloud(df_total_titulo$word, df_total_titulo$freq, min.freq= 2,
max.words= 100, random.order= FALSE,
rot.per= 0.15, colors=brewer.pal(8, "Dark2"),
scale=c(5, .7))
})
# Plot number of spoken words
output$numb_spoken_words <- renderPlotly({
all_vid_nerdologia %>%
arrange(publication_date) %>%
mutate(n_words_spoken = str_count(html_page_text_sorted, "\\S+")) %>%
plot_ly() %>%
add_trace(x = ~publication_date, y = ~n_words_spoken,
name = 'Number of words spoken during video recording', type = 'scatter',
mode = "markers+lines", text = ~paste('Video: ', title, '\n', 'Number of words: ', n_words_spoken),
line = list(color = '#004080', width = 4)) %>%
layout(xaxis = list(title = "Publication date"),
yaxis = list (title = "Number of words"),
font = list(size = 14),
hovermode = 'compare',
legend = list(orientation = 'h'))
})
}
shinyApp(ui, server)Este é o resultado:
Em (I) temos um gráfico de linha que segue de acordo com o tempo do início até o presente momento do canal. Cada ponto se trata de um vídeo sendo o gráfico responsivo ao cursor do mouse, também com a legenda clicável. Toda vez que o usuário passar o cursor sobre um ponto, automaticamente será gerado um wordcloud (II) deste vídeo (no caso, o que o Youtuber falou). Em (III) temos os Top vídeos mais curtidos, odiados e comentados. O wordcloud em (IV) foi gerado a partir dos títulos dos vídeos do canal. Por fim, fiz uma contagem de palavras ditas ao longo do tempo (deveria ter plotado o tempo de vídeo….será?). Me parece que o número de views declina no decorrer do tempo ao passo que a quantidade de palavras ditas aumenta. D:. Pode ser uma relação errônea.
O dashboard online pode ser acessado neste Link :D
https://daviinada.shinyapps.io/youtubeapp/