library(caret)
library(mice)
library(dplyr)
library(ggplot2)
library(stringr)
library(purrr)
library(corrplot)
library(viridis)
library(RColorBrewer)1.Tratamento inicial dos dados
Unindo o conjunto de treino e teste para estimar pseudo valores. Existem muitos dados faltantes, e para estimar um valor mais próximo do real para os mesmos, precisaremos do máximo de informação possível.
setwd('/home/davi/Desktop/titanic')
train <- read.csv(file='train.csv', sep=',', stringsAsFactors = FALSE)
train$dataTag <- 'train'
test <- read.csv(file='test.csv', sep=',', stringsAsFactors = FALSE)
test$dataTag <- 'test'
test$Survived <- NA
concat_data <- train %>% bind_rows(test)
head(concat_data)## PassengerId Survived Pclass
## 1 1 0 3
## 2 2 1 1
## 3 3 1 3
## 4 4 1 1
## 5 5 0 3
## 6 6 0 3
## Name Sex Age SibSp
## 1 Braund, Mr. Owen Harris male 22 1
## 2 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1
## 3 Heikkinen, Miss. Laina female 26 0
## 4 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1
## 5 Allen, Mr. William Henry male 35 0
## 6 Moran, Mr. James male NA 0
## Parch Ticket Fare Cabin Embarked dataTag
## 1 0 A/5 21171 7.2500 S train
## 2 0 PC 17599 71.2833 C85 C train
## 3 0 STON/O2. 3101282 7.9250 S train
## 4 0 113803 53.1000 C123 S train
## 5 0 373450 8.0500 S train
## 6 0 330877 8.4583 Q trainsummary(concat_data)## PassengerId Survived Pclass Name
## Min. : 1 Min. :0.0000 Min. :1.000 Length:1309
## 1st Qu.: 328 1st Qu.:0.0000 1st Qu.:2.000 Class :character
## Median : 655 Median :0.0000 Median :3.000 Mode :character
## Mean : 655 Mean :0.3838 Mean :2.295
## 3rd Qu.: 982 3rd Qu.:1.0000 3rd Qu.:3.000
## Max. :1309 Max. :1.0000 Max. :3.000
## NA's :418
## Sex Age SibSp Parch
## Length:1309 Min. : 0.17 Min. :0.0000 Min. :0.000
## Class :character 1st Qu.:21.00 1st Qu.:0.0000 1st Qu.:0.000
## Mode :character Median :28.00 Median :0.0000 Median :0.000
## Mean :29.88 Mean :0.4989 Mean :0.385
## 3rd Qu.:39.00 3rd Qu.:1.0000 3rd Qu.:0.000
## Max. :80.00 Max. :8.0000 Max. :9.000
## NA's :263
## Ticket Fare Cabin
## Length:1309 Min. : 0.000 Length:1309
## Class :character 1st Qu.: 7.896 Class :character
## Mode :character Median : 14.454 Mode :character
## Mean : 33.295
## 3rd Qu.: 31.275
## Max. :512.329
## NA's :1
## Embarked dataTag
## Length:1309 Length:1309
## Class :character Class :character
## Mode :character Mode :character
##
##
##
## Formatando os dados. Precisamos marcas as regiões com dados faltantes e também definir os tipos de cada variável (categórico, numérico ou string) do nosso conjunto de dados.
concat_data$Cabin[which(concat_data$Cabin == '')] <- NA
concat_data$Embarked[which(concat_data$Embarked == '')] <- NA
concat_data$Survived <- as.factor(concat_data$Survived)
concat_data$Pclass <- as.factor(concat_data$Pclass)
concat_data$Sex <- as.factor(concat_data$Sex)
concat_data$Ticket <- as.factor(concat_data$Ticket)
concat_data$Cabin <- as.factor(concat_data$Cabin)
concat_data$Embarked <- as.factor(concat_data$Embarked)
concat_data$dataTag <- as.factor(concat_data$dataTag)# Tem um NA tambem, pertence a Pclass 3, vou substituir pela media dessa classe
which(is.na(concat_data$Fare))## [1] 1044concat_data[1044, ]## PassengerId Survived Pclass Name Sex Age SibSp Parch
## 1044 1044 <NA> 3 Storey, Mr. Thomas male 60.5 0 0
## Ticket Fare Cabin Embarked dataTag
## 1044 3701 NA <NA> S test# Substituindo
concat_data$Fare[1044] <- mean( concat_data$Fare[which(concat_data$Pclass == 3)], na.rm = TRUE)
# Observei 2 NA's em Embarked
concat_data[ which(is.na(concat_data$Embarked)), ]## PassengerId Survived Pclass Name
## 62 62 1 1 Icard, Miss. Amelie
## 830 830 1 1 Stone, Mrs. George Nelson (Martha Evelyn)
## Sex Age SibSp Parch Ticket Fare Cabin Embarked dataTag
## 62 female 38 0 0 113572 80 B28 <NA> train
## 830 female 62 0 0 113572 80 B28 <NA> train# Onde sera que eles embarcaram?
# Por serem classe 1, provavelmente embarcaram em S ou C
table(concat_data$Embarked, concat_data$Pclass)##
## 1 2 3
## C 141 28 101
## Q 3 7 113
## S 177 242 495concat_data$Embarked[ which(is.na(concat_data$Embarked)) ] <- factor("S")2.Definindo novas variáveis
A partir dos nomes, irei separar o sobrenome e o pronome de tratamento para ajudar a indentificar melhor todos os subgrupos de passageiros.
length(concat_data$Name) # n nomes## [1] 1309# preciso tratar melhor, fazer split na virgula e no ponto para capturar o sobrenome e o pronome de tratamento
names <- strsplit(concat_data$Name, ',')
names_no_space <- lapply(names, function(x) gsub(' ', '',x))
# Sobrenpome
surname <- lapply(names_no_space , function(x) x[[1]] )
surname <- unlist(surname)
treat_pron <- lapply(names_no_space , function(x) x[[2]])
treat_pron <- lapply(treat_pron, function(x) strsplit(x, '\\.', perl = TRUE)[[1]])
treat_pron <- map(treat_pron, 1) %>% unlist()
# Adicionando as novas colunas
concat_data$surname <- as.factor(surname)
concat_data$treat_pron <- as.factor(treat_pron)
head(concat_data)## PassengerId Survived Pclass
## 1 1 0 3
## 2 2 1 1
## 3 3 1 3
## 4 4 1 1
## 5 5 0 3
## 6 6 0 3
## Name Sex Age SibSp
## 1 Braund, Mr. Owen Harris male 22 1
## 2 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1
## 3 Heikkinen, Miss. Laina female 26 0
## 4 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1
## 5 Allen, Mr. William Henry male 35 0
## 6 Moran, Mr. James male NA 0
## Parch Ticket Fare Cabin Embarked dataTag surname
## 1 0 A/5 21171 7.2500 <NA> S train Braund
## 2 0 PC 17599 71.2833 C85 C train Cumings
## 3 0 STON/O2. 3101282 7.9250 <NA> S train Heikkinen
## 4 0 113803 53.1000 C123 S train Futrelle
## 5 0 373450 8.0500 <NA> S train Allen
## 6 0 330877 8.4583 <NA> Q train Moran
## treat_pron
## 1 Mr
## 2 Mrs
## 3 Miss
## 4 Mrs
## 5 Mr
## 6 MrVamos ver a distribuição da idade. Menores de idade possuem o pronome de tratamento Master.
colorRampPalette(brewer.pal(9, "Set1"))## function (n)
## {
## x <- ramp(seq.int(0, 1, length.out = n))
## if (ncol(x) == 4L)
## rgb(x[, 1L], x[, 2L], x[, 3L], x[, 4L], maxColorValue = 255)
## else rgb(x[, 1L], x[, 2L], x[, 3L], maxColorValue = 255)
## }
## <bytecode: 0x7546de8>
## <environment: 0x7545ad0>concat_data %>%
select(Age, treat_pron) %>%
na.omit() %>%
ggplot(aes(y=Age, x=treat_pron)) +
geom_boxplot( fill= 'deepskyblue3') +
theme(legend.text = element_text(size=12),
axis.text.x = element_text(size=10, angle = 0),
axis.title=element_text(size=12),
axis.text = element_text(size=12),
axis.line = element_line(colour = "black"),
panel.border = element_blank()) +
theme_bw()
3.Estimando pseudo valores para idade
3.1.Método II
Minha primeira estrategia será utilizar a idade média de cada classe para preencher os dados faltantes, ao invés de simplesmente usar uma média global.
class_with_na <- concat_data$treat_pron[is.na(concat_data$Age)]
as.character(class_with_na) %>% table()## .
## Dr Master Miss Mr Mrs Ms
## 1 8 50 176 27 1mean_age_by_class <- concat_data %>%
filter(str_detect(treat_pron, "Dr|Miss|Mr|Mrs|Ms|Master")) %>%
dplyr::group_by(treat_pron) %>%
dplyr::summarize(mean_age = mean(Age, na.rm = TRUE))
mean_age_by_class## # A tibble: 6 x 2
## treat_pron mean_age
## <fctr> <dbl>
## 1 Dr 43.6
## 2 Master 5.48
## 3 Miss 21.8
## 4 Mr 32.3
## 5 Mrs 37.0
## 6 Ms 28.0for(i in 1:nrow(concat_data)){
if(is.na(concat_data$Age[i]) & concat_data$treat_pron[i] == 'Dr'){
concat_data$Age[i] <- 43.6
}
if(is.na(concat_data$Age[i]) & concat_data$treat_pron[i] == 'Miss'){
concat_data$Age[i] <- 21.8
}
if(is.na(concat_data$Age[i]) & concat_data$treat_pron[i] == 'Mr'){
concat_data$Age[i] <- 32.3
}
if(is.na(concat_data$Age[i]) & concat_data$treat_pron[i] == 'Mrs'){
concat_data$Age[i] <- 37.0
}
if(is.na(concat_data$Age[i]) & concat_data$treat_pron[i] == 'Ms'){
concat_data$Age[i] <- 28.0
}
if(is.na(concat_data$Age[i]) & concat_data$treat_pron[i] == 'Master'){
concat_data$Age[i] <- 5.48
}
}
summary(concat_data)## PassengerId Survived Pclass Name Sex
## Min. : 1 0 :549 1:323 Length:1309 female:466
## 1st Qu.: 328 1 :342 2:277 Class :character male :843
## Median : 655 NA's:418 3:709 Mode :character
## Mean : 655
## 3rd Qu.: 982
## Max. :1309
##
## Age SibSp Parch Ticket
## Min. : 0.17 Min. :0.0000 Min. :0.000 CA. 2343: 11
## 1st Qu.:21.80 1st Qu.:0.0000 1st Qu.:0.000 1601 : 8
## Median :30.00 Median :0.0000 Median :0.000 CA 2144 : 8
## Mean :29.90 Mean :0.4989 Mean :0.385 3101295 : 7
## 3rd Qu.:36.00 3rd Qu.:1.0000 3rd Qu.:0.000 347077 : 7
## Max. :80.00 Max. :8.0000 Max. :9.000 347082 : 7
## (Other) :1261
## Fare Cabin Embarked dataTag
## Min. : 0.000 C23 C25 C27 : 6 C:270 test :418
## 1st Qu.: 7.896 B57 B59 B63 B66: 5 Q:123 train:891
## Median : 14.454 G6 : 5 S:916
## Mean : 33.280 B96 B98 : 4
## 3rd Qu.: 31.275 C22 C26 : 4
## Max. :512.329 (Other) : 271
## NA's :1014
## surname treat_pron
## Andersson: 11 Mr :757
## Sage : 11 Miss :260
## Asplund : 8 Mrs :197
## Goodwin : 8 Master : 61
## Davies : 7 Dr : 8
## Brown : 6 Rev : 8
## (Other) :1258 (Other): 183.2.Método II
A segunda estratégia consiste em realizar uma regressão da idade usando random forest.
# Ordenar por sobrenome
concat_data <- concat_data %>%
arrange(surname)
train_na <- concat_data %>%
select(Age, Pclass, SibSp, Parch, Fare, treat_pron,Sex) %>%
na.omit()
age_model <- train(Age ~ Pclass + Sex + SibSp + Parch +
Fare + surname + treat_pron ,
data = train_na,
method = 'rf',
tuneGrid = data.frame(mtry = c(2,3,4,5,6,8,10)),
trControl = trainControl(method = 'cv', number = 10,
verboseIter = TRUE))
plot(age_model)
print(age_model)
summary(age_model)
pred_age <- predict(age_model, concat_data)
concat_data$Age[which(is.na(concat_data$Age))] <- pred_age[which(is.na(concat_data$Age))]3.3.Método III
Terceira tentativa: fazer regressão linear multipla
age_model2 <- lm(Age ~ Pclass + SibSp + Parch + treat_pron,
data = train_na)
summary(age_model2)
plot(age)
pred_age <- predict(age_model2, concat_data)
concat_data$Age[which(is.na(concat_data$Age))] <- pred_age[which(is.na(concat_data$Age))]4.Explorando os dados
Com os valores faltantes estimados, podemos analisar melhor os dados.
Idade x morte x sexo
Do total de homens, a maioria morreu. Do total de mulheres, a maioria sobreviveu.
concat_data %>%
select(Age, Sex, Survived) %>%
na.omit()%>%
ggplot(aes(y=Age, x=Sex , fill=Survived, size= Age)) +
geom_boxplot(alpha = 1) +
scale_fill_manual(values = c('#330033', '#008080')) +
theme_bw()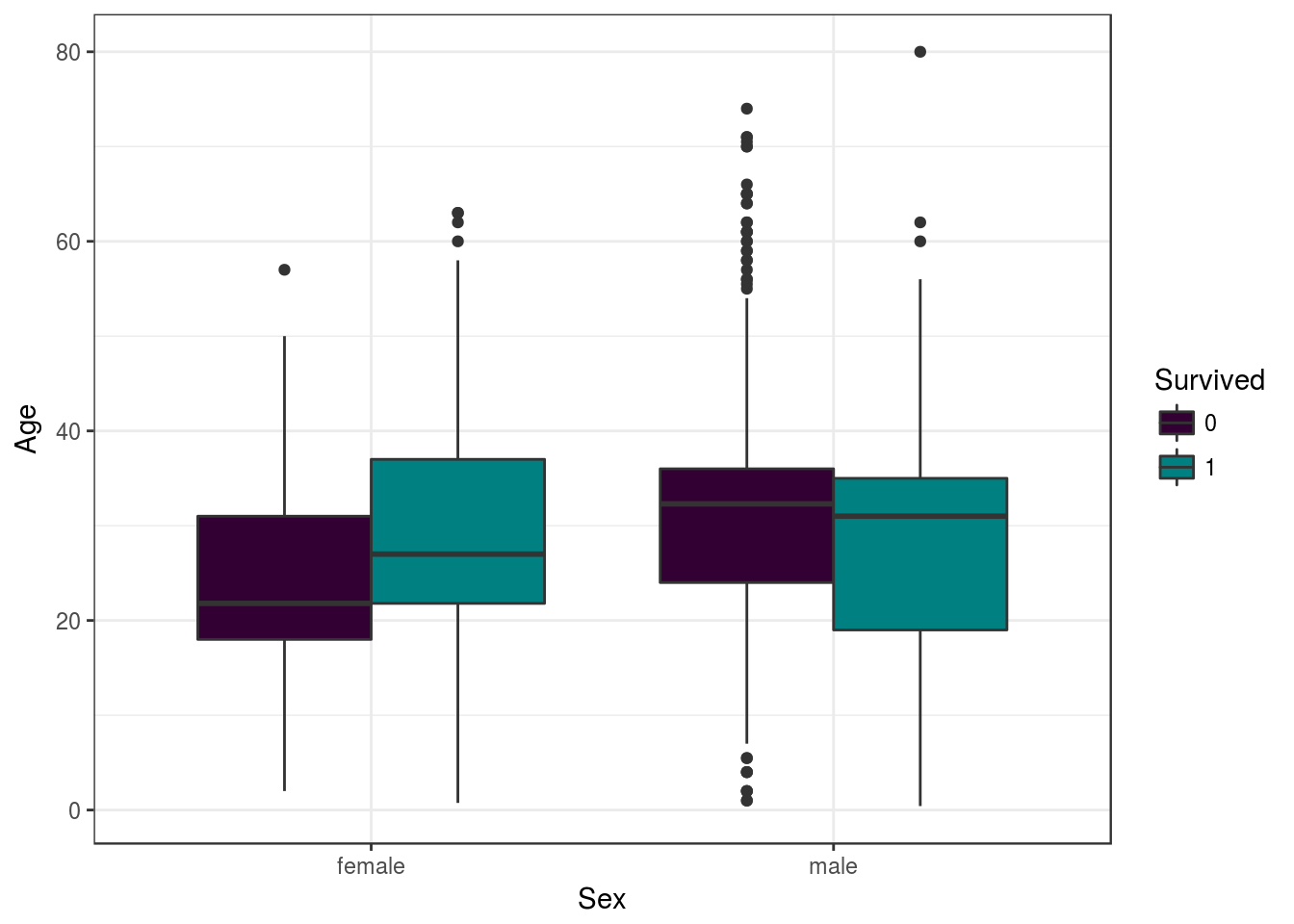
Dos que sobreviveram, boa parte tinha entre 20 a 30 anos, seja homem ou mulher
concat_data %>%
select(Age, Sex, Survived, treat_pron) %>%
na.omit()%>%
ggplot(aes(y=Age, x=treat_pron , fill=Survived)) +
geom_boxplot(alpha = 0.8)+
geom_hline(yintercept = c(20, 30, 40), color = 'red', linetype= 3) +
scale_fill_manual(values = c('#330033', '#008080')) +
theme_bw() 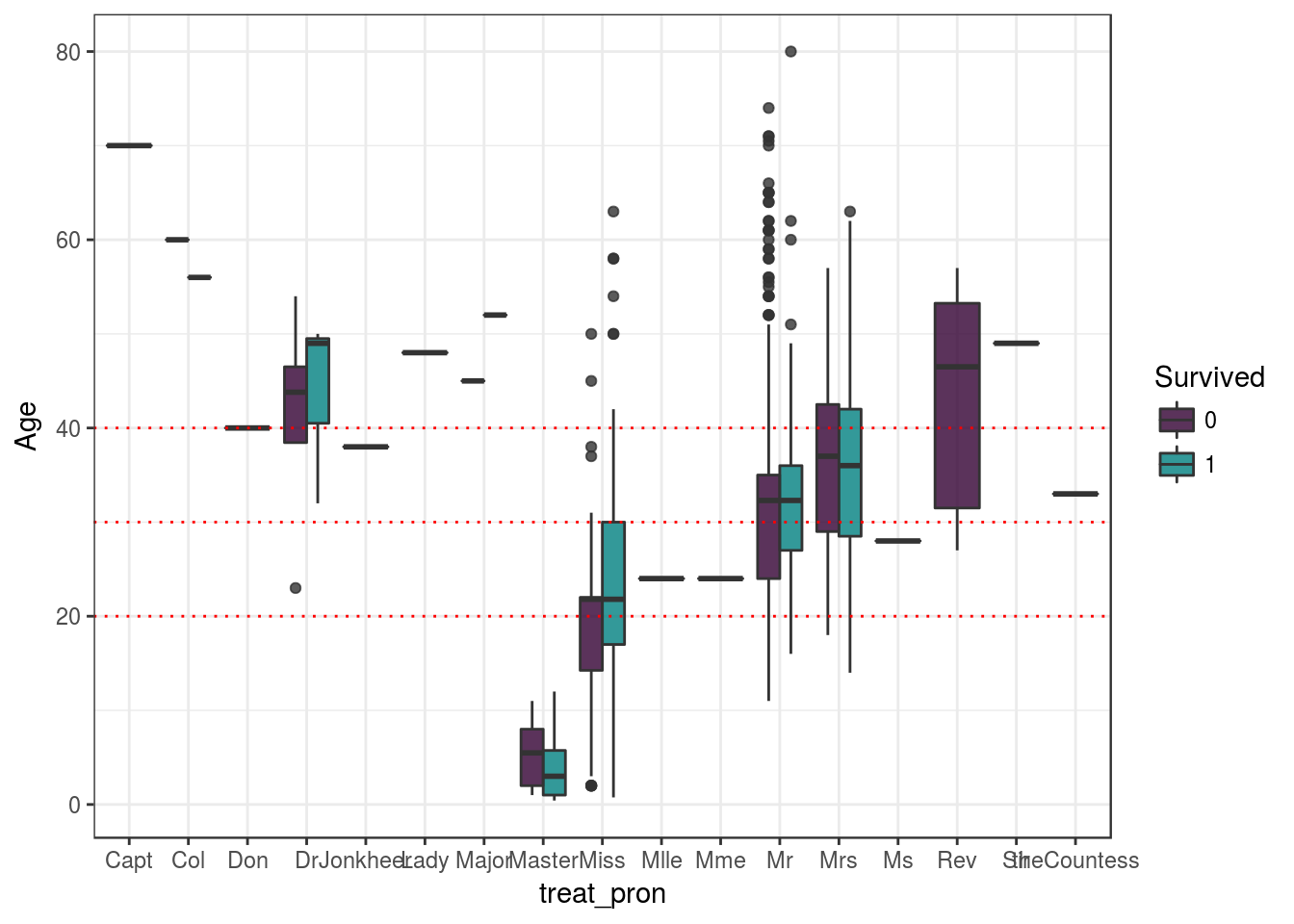
concat_data %>%
select(Age, Sex, Survived, treat_pron) %>%
na.omit()%>%
ggplot(aes(y=Age, x=treat_pron , col=Survived) ) +
geom_point(alpha = 0.5, size=3, position = position_jitterdodge()) +
scale_color_manual(values = c('#330033', '#008080')) +
theme_bw() 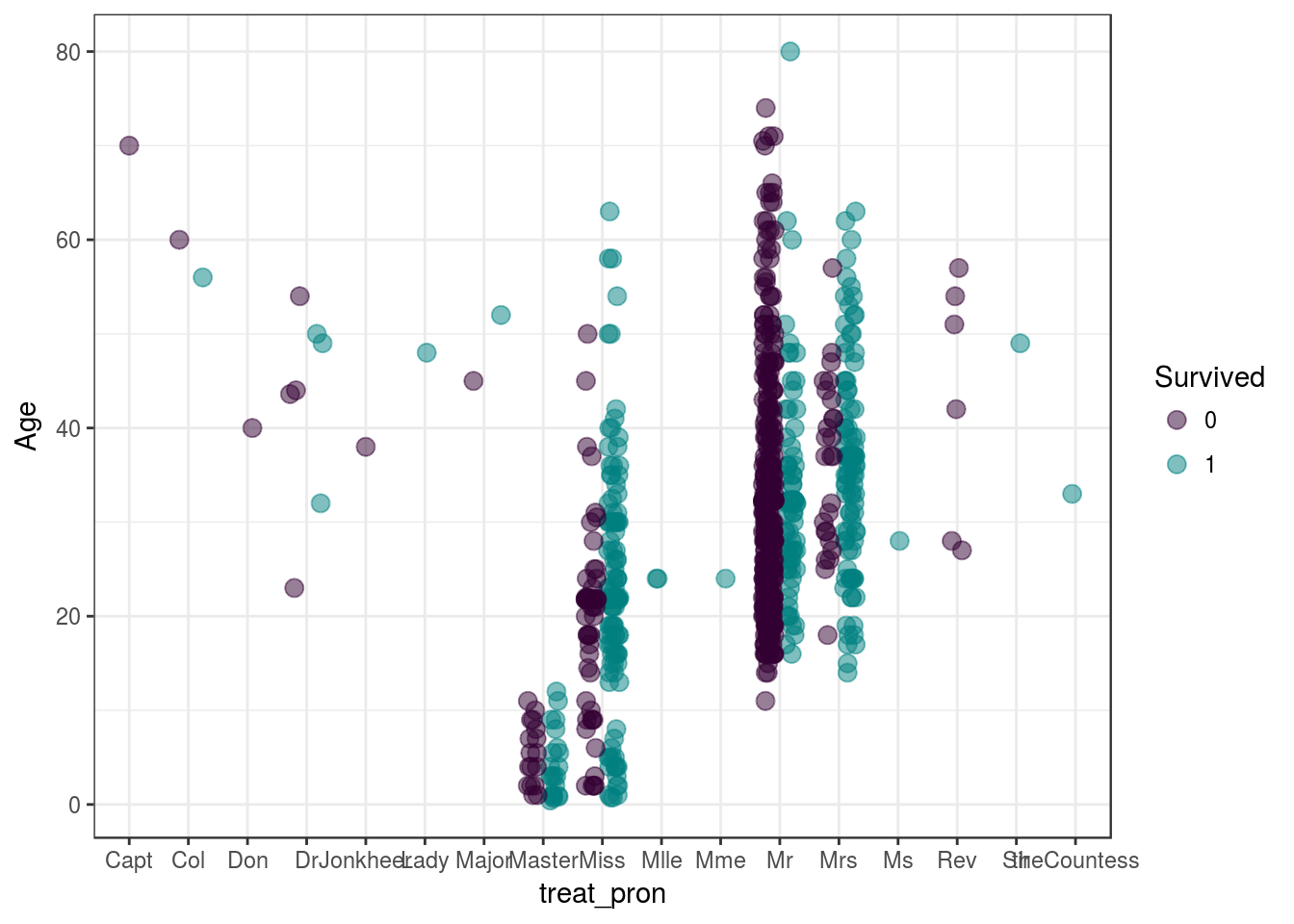
# Classe vs Tarifa
# A classe 1 ten yna tarifa consideravelmente mais cara (sao os passageiros ricos)
concat_data %>%
ggplot(aes(x=Pclass, y=Fare)) +
geom_boxplot(fill='cornflowerblue') +
theme_bw()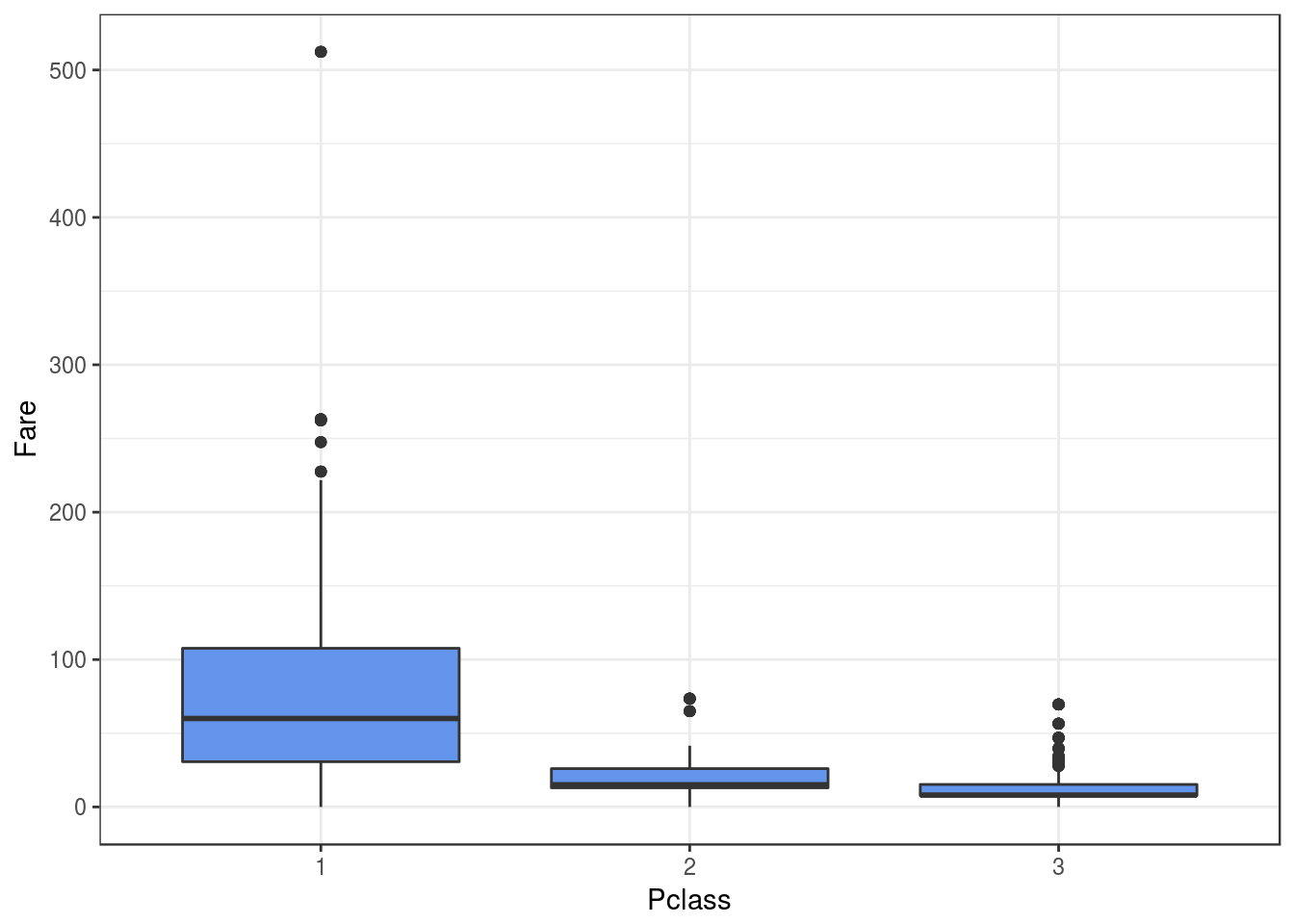
Os mais privilegiados morreram menos que os demais?
Com os dados observados até então, parece que as pessoas da classe 3 morreram mais (50%). Seria uma questao de localizacao do navio?
concat_data %>%
na.omit() %>%
ggplot(aes(x=Pclass, fill=Survived)) +
geom_bar(position = 'fill', alpha=0.8) +
scale_fill_manual(values = c('#330033', '#008080')) +
theme_bw()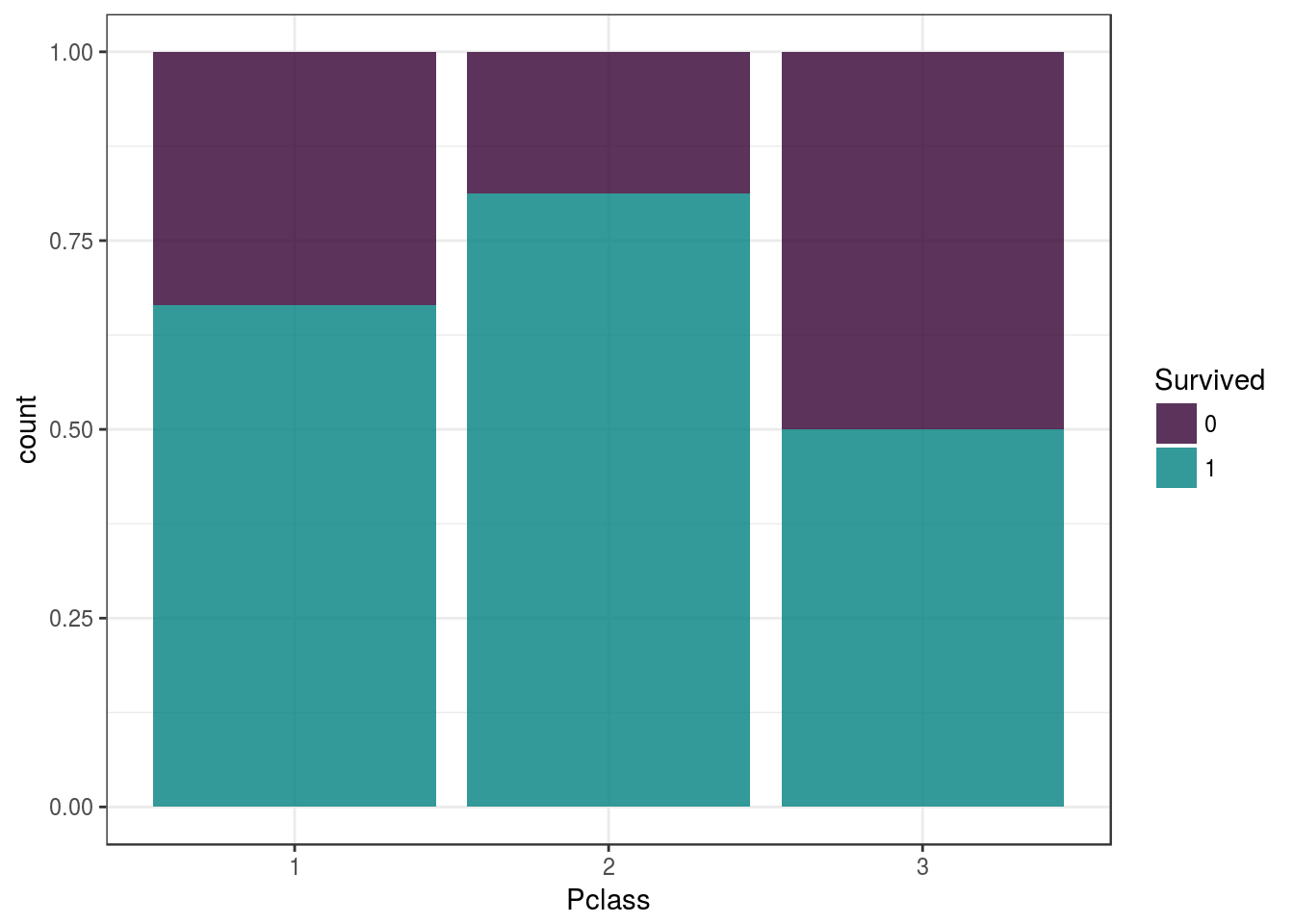
Conforme a figura, podemos ver que a classe 1, se situa mais ao centro das classes 2 e 3. A classe 3 se situa na ponta traseira do navio.
Será que o navio afundou primeiramente pela parte traseira? Se sim, essa observação parece ser bem plausível.

Vamos ver se existe alguma relação linear entre os dados
dist_df_vars <- concat_data %>%
select(Pclass, Age, SibSp, Parch, Fare)
dist_df_vars$Pclass <- as.numeric(dist_df_vars$Pclass)
vars_cor <- cor(dist_df_vars, method = 'pearson')
corrplot(vars_cor, method = 'ellipse', type="upper", order="hclust", addCoef.col = "black")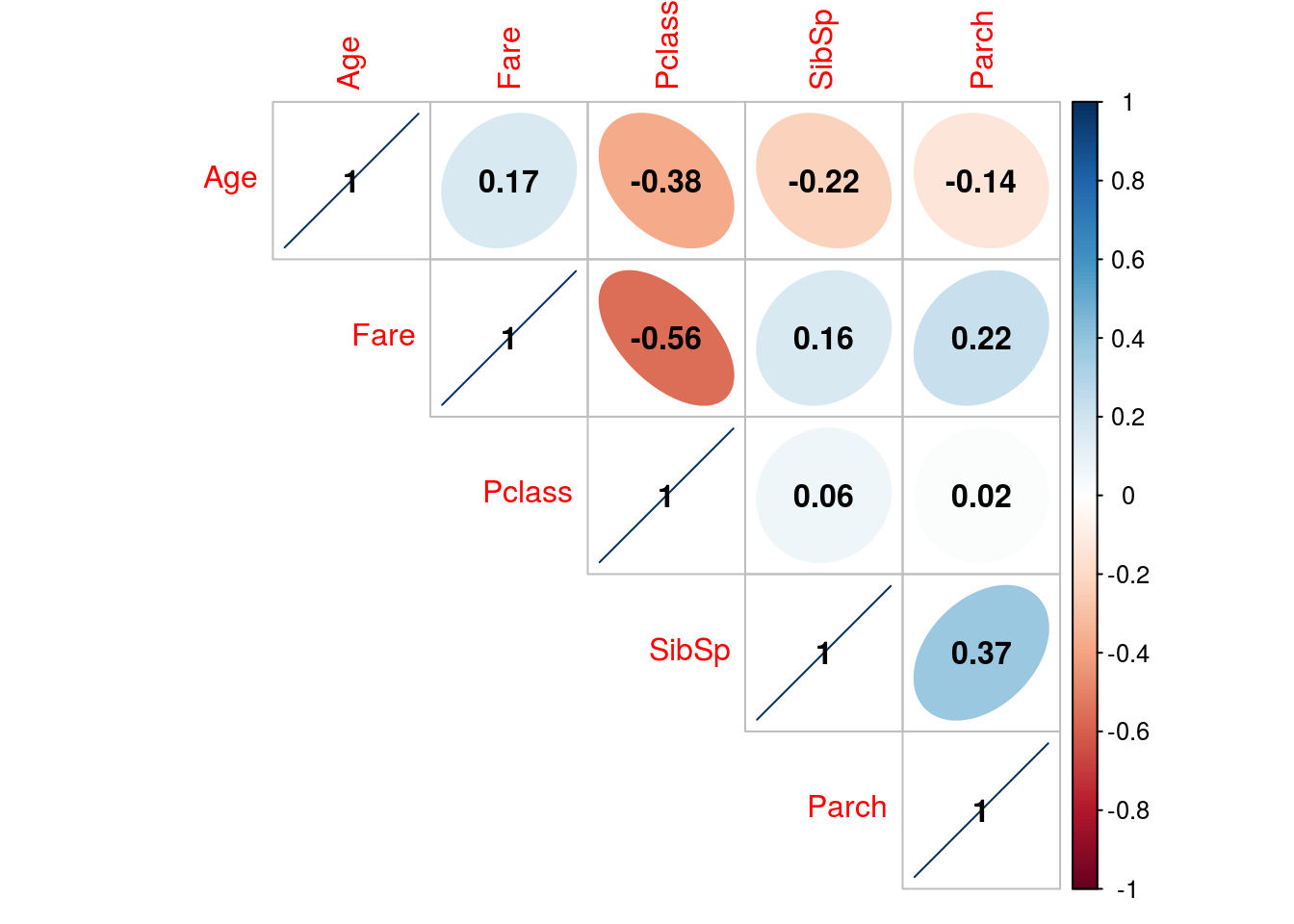
5.Treinando e classificando os dados
Hora de aplicar os métodos de classificação sobre os dados de treinamento. Antes disso, precisamos separar novamente os dados em duas partes, a parte de treinamento e a de teste.
Faremos testes usando Random forest e Regressão logística para classificar quem sobreviveu e quem não sobreviveu ao desastre.
train <- concat_data %>% filter(dataTag == 'train')
test <- concat_data %>% filter(dataTag == 'test')5.1.Random Forest
final_model <- train(Survived ~ Pclass + Sex + Age + SibSp + Parch +
Fare + surname + treat_pron,
data= train,
method= 'rf',
tuneGrid= data.frame(mtry= c(2,3,4,5,6,8,10)),
trControl= trainControl(method= 'cv', number= 10,
verboseIter= TRUE))
pred_surv <- predict(final_model, test)
to_submit <- data.frame(PassengerId = test$PassengerId, Survived = pred_surv)
write.csv(file='to_submit.csv', to_submit, row.names = F)print(final_model)plot(final_model)5.2.Regressão logística
logist_regression <- glm(Survived ~ Pclass + Sex + Age + SibSp + Fare,
data = train, family = 'binomial')
pred_surv <- predict(logist_regression, test, type = 'response')
pred_cutoff_90 <- ifelse(pred_surv >= 0.90, 1, 0)
pred_cutoff_60 <- ifelse(pred_surv >= 0.60, 1, 0)
to_submit <- data.frame(PassengerId = test$PassengerId, Survived = pred_cutoff_60)
write.csv(file='to_submit.csv', to_submit, row.names = F)summary(logist_regression)##
## Call:
## glm(formula = Survived ~ Pclass + Sex + Age + SibSp + Fare, family = "binomial",
## data = train)
##
## Deviance Residuals:
## Min 1Q Median 3Q Max
## -2.7782 -0.5967 -0.4199 0.6163 2.5135
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 3.959967 0.446512 8.869 < 2e-16 ***
## Pclass2 -1.100803 0.292908 -3.758 0.000171 ***
## Pclass3 -2.262839 0.290373 -7.793 6.55e-15 ***
## Sexmale -2.695011 0.194883 -13.829 < 2e-16 ***
## Age -0.042567 0.007844 -5.427 5.74e-08 ***
## SibSp -0.399149 0.106066 -3.763 0.000168 ***
## Fare 0.002389 0.002328 1.026 0.304703
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 1186.66 on 890 degrees of freedom
## Residual deviance: 784.86 on 884 degrees of freedom
## AIC: 798.86
##
## Number of Fisher Scoring iterations: 56.Resultados da submissão no Kaggle
A métrica de avaliação de desemenho usada foi a acurácia. Que mede o total de acertos sobre o total de observações. Após diversos testes e diferentes combinações de parâmetros de classificação, o melhor resultado obtido foi de 0.78468
Score obtido

